Beyond Chatbots: The Rise of Large Action Models (LAMs)

Architecting Large Action Models: Bridging the Gap Between Probabilistic Intent and Deterministic Execution
At 10 million requests per day, "99% accuracy" is not a KPI. It is an incident report waiting to happen.
In a standard RAG (Retrieval-Augmented Generation) setup, a 1% hallucination rate means a user gets a slightly weird summary. They refresh, they move on. But we aren't building chat interfaces anymore. We are building Large Action Models (LAMs)—systems that touch money, mutate database states, and trigger third-party APIs.
Do the math. If you chain five autonomous steps—search, analyze, plan, draft, execute—and each holds a 99% success rate, your system reliability crashes to $0.99^5 \approx 95%$. At scale, that is 500,000 failed transactions daily. In payments or healthcare, that isn't a bug; it's a resume-generating event.
Marketing slide decks claim "Agentic AI" handles this autonomously. They are wrong. As architects, our job is to wrap the probabilistic chaos of an LLM in the deterministic straightjacket of distributed systems engineering. We don't replace code with AI; we orchestrate AI with rigid, unforgiving code.
Here is how you build a LAM runtime that survives production.
The Compounding Error Problem
The difference between a chatbot and an agent is the blast radius. Chatbots have read-only failure modes (misinformation). Agents have write-access failure modes (data corruption, financial loss, cascading outages).
The Mathematics of Autonomy
In a monolithic script, logic is deterministic: If X, then Y. In an agentic workflow, logic is probabilistic: Given context X, the most likely next token implies Y.
Recent research, specifically Large Action Models: From Inception to Implementation (Arxiv, 2024), highlights "error propagation." In a multi-turn agent workflow, errors don't add up; they compound.
Consider a standard "Travel Agent" workflow:
- Intent Recognition: User wants a flight. (99% acc)
- Tool Selection: Choose
Skyscanner_API. (98% acc) - Parameter Extraction: Extract dates/destinations. (95% acc)
- API Execution: Call API. (99.9% reliability)
- Response Synthesis: Summarize flight options. (99% acc)
System Reliability: $0.99 \times 0.98 \times 0.95 \times 0.999 \times 0.99 \approx 91%$.
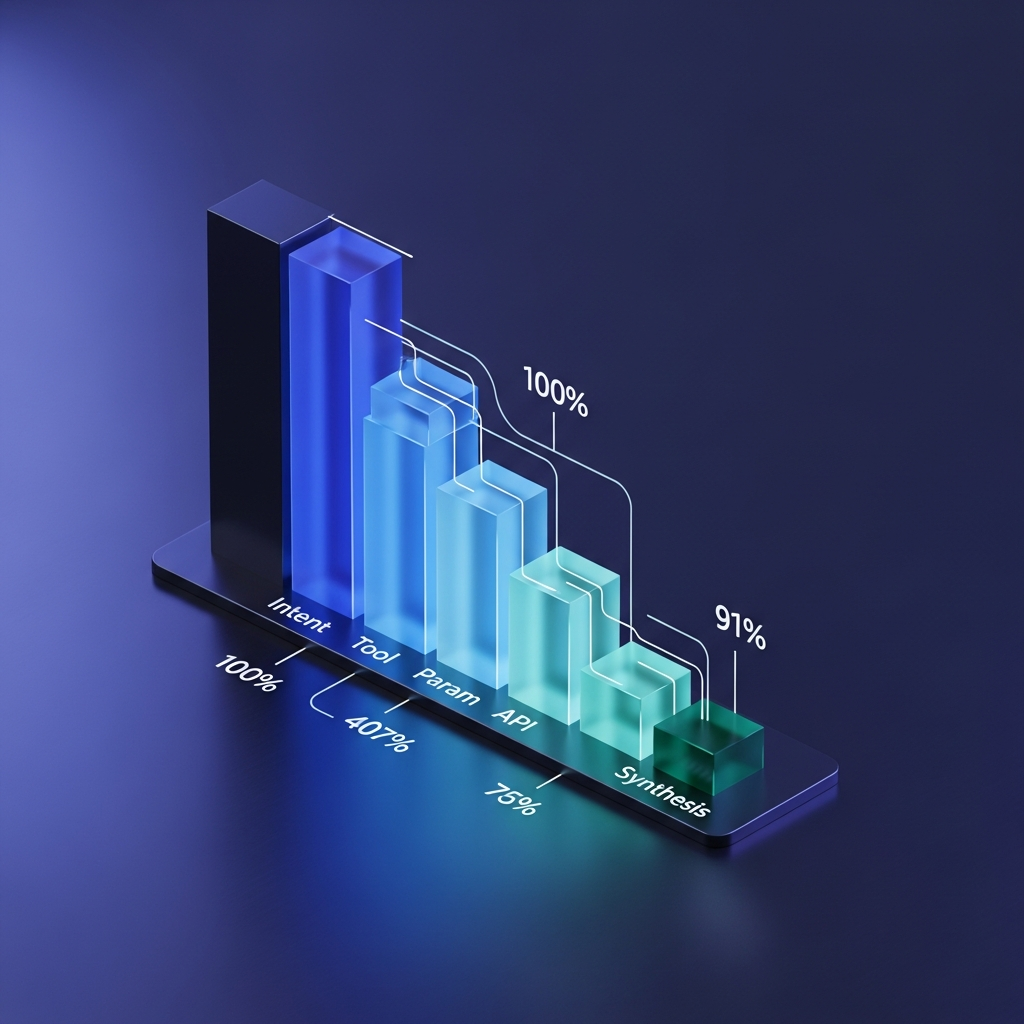
A 9% failure rate is unacceptable for enterprise software. Worse, "failure" here doesn't mean an exception is thrown. It means the system silently books a flight for the wrong date.
The Architect's Trade-off
To mitigate this, you must trade autonomy for observability. Never allow the model to execute the full chain in a single "black box" inference pass.
Architecture Decision: Break the workflow into discrete, atomic steps where state is persisted externally, not in the context window.
- Improves: Debuggability, recoverability, and intermediate validation.
- Costs: Latency (multiple round-trips add ~200-500ms per step) and token costs (re-sending context).
Anatomy of a LAM Runtime: Beyond the 'While Loop'
The naive implementation of an agent looks like this (common in LangChain tutorials):
# DO NOT DEPLOY THIS TO PRODUCTION
while not task.is_complete():
action = model.predict(task, history)
result = execute(action)
history.append(result)
At scale, this pattern creates Livelocks. The model encounters an API error, apologizes ("I'm sorry, let me try again"), and retries the exact same invalid action until the context window overflows or your token budget burns to the ground.
The Cognitive Router Pattern
Production LAMs require a Cognitive Router architecture. This separates the Reasoning Engine (the LLM) from the Execution Engine (deterministic code).
The LLM does not call the API. The LLM outputs a Structured Intent.
The Flow:
- Input: User Request.
- Cognitive Router (LLM): Analyzes request and outputs a JSON intent object.
- Policy Layer (Code): Validates the intent against schema and business rules.
- Executor (Code): Calls the actual API.
- Feedback Loop: Result is fed back to the Router.

Constrained Decoding with Grammars
Do not rely on "prompt engineering" to get valid JSON. Use Formal Grammars (BNF or Regex constraints) during the decoding phase. This forces the model to select tokens that conform to a specific schema.
Implementation Example (GBNF / Llama.cpp style):
root ::= object
object ::= "{" space pair ("," space pair)* "}" space
pair ::= string ":" space value
string ::= "\"" [^"]* "\"" space
value ::= object | array | string | number | boolean | null
By enforcing a grammar at the inference engine level (e.g., using llama.cpp grammars or OpenAI's Structured Outputs), you eliminate the "parsing error" failure class entirely.
Trade-off:
- Improves: Reliability. 0% chance of malformed JSON.
- Costs: Flexibility. The model cannot "explain" its reasoning outside the JSON structure. You may need a separate "reasoning" field in your schema, consuming more tokens.
State Management and Idempotency
The most dangerous misconception in agent design is treating the LLM's context window as the database. The context window is ephemeral, expensive, and prone to "forgetting" instructions as it fills up (the "Lost in the Middle" phenomenon).
Externalized State Machines (FSM)
For a 10M request/day system, workflow state must reside in a durable store (Redis, Postgres), managed by a Finite State Machine (FSM). The LLM is merely a stateless function that transitions the FSM from one state to another.
Architecture Pattern:
- Load State: Fetch current workflow status from Redis.
- Prompt Construction: Inject only the relevant context for the current state into the LLM.
- Transition: LLM selects the next transition.
- Persist: Update Redis.
This decouples workflow progress from the model's memory. If the model hallucinates, we roll back the FSM, not the conversation history.
The Idempotency Imperative
When an agent fails a step and retries, it must not duplicate side effects.
- Scenario: Agent decides to
pay_invoice(id=123). - Failure: The API times out, but the payment processed on the backend.
- Retry: Agent sees a timeout error and retries
pay_invoice(id=123). - Result: Double payment.
Requirement: Every tool exposed to a LAM must be idempotent.
- Implementation: The Execution Engine generates a unique
idempotency_key(hash of the workflow ID + step ID) for every write action. The downstream API checks this key before processing.
If your legacy APIs are not idempotent, you cannot safely expose them to an autonomous agent. You must build a middleware layer to handle deduplication.
The Governance Turn: Treating the Model as an Untrusted User
Security teams often ask: "How do we prevent the AI from doing something bad?" The answer is simple: Don't give the AI permission to do anything.
The Sandboxed Executive Pattern
Treat the LLM as an untrusted external user. It gets no root access. It gets no admin access. It has a specific, scoped role.
The "Signed Intent" Protocol:
- Intent Generation: The LLM generates a request:
{"action": "delete_user", "uid": "8821"}. - Policy Check: A deterministic code layer intercepts this request. It checks:
- RBAC: Does the user who initiated the chat have permission to delete users?
- Scope: Is this user in the same organization?
- Heuristics: Is this the 50th deletion request in 1 minute? (Rate limiting).
- Execution: Only if all checks pass does the code execute the function.
This prevents Hallucinated Privilege Escalation, where the model "thinks" it is an admin because the system prompt told it "You are a helpful administrator." The system prompt is text; the Policy Layer is code. Code wins.
The State of AI in 2024-2025
According to The State of AI in 2024-2025 (McKinsey), the primary bottleneck for enterprise adoption has shifted from "proof of concept" to "risk management." The report highlights that organizations successfully scaling generative AI are those implementing rigorous risk frameworks rather than relying on model capabilities alone.
We are seeing a shift toward "Model-as-User" governance. Instead of trying to align the model to be "safe" (probabilistic), we apply Zero Trust principles to the model's outputs (deterministic). This architectural shift is the only viable path to securing LAMs at scale.
Observability: Debugging the 'Black Box'
Standard APM tools like Datadog or New Relic are insufficient for LAMs. They tell you that an error occurred (500 Internal Server Error), but they don't tell you why the model decided to call the wrong endpoint.
Decision Tracing
We need a new telemetry primitive: the Decision Trace. A Decision Trace must capture:
- The Input Context: What exactly did the model see? (Prompt snapshot).
- The Reasoning Chain: The "Chain of Thought" output (hidden from user, visible to devs).
- The Rejected Candidates: Did the model consider the correct tool but discard it?
- The Output Probability: What was the log-prob of the selected action token?
Metric: Agent Drift We must measure Agent Drift—the divergence of the agent's behavior from a "Golden Path" over time.
- Setup: Run a synthetic test suite of 100 common requests every hour.
- Measure: How many steps does it take to solve the problem?
- Alert: If the average step count increases from 3.2 to 4.5, your model has drifted (or the underlying model API has changed behavior).
Metric: Token-to-Action Ratio Efficiency matters. Track the ratio of input tokens consumed to successful actions taken. A spiking ratio indicates the agent is spinning in reasoning loops without executing value.
Production Readiness: The Migration from RAG to LAM
Moving from "Chat with your PDF" to "Execute this Workflow" is not a feature update; it is a platform migration.
The Maturity Model
- Human-in-the-Loop (HITL): The agent plans the action, but a human must click "Approve."
- Use Case: Draft email, propose SQL query.
- Human-on-the-Loop: The agent executes automatically, but a human monitors a real-time feed and has a "Kill Switch."
- Use Case: Customer support tier 1 triage.
- Human-out-of-the-Loop (Audit Only): The agent executes autonomously. Humans review post-hoc samples.
- Use Case: High-volume, low-risk data entry.
The "Undo" Button (Compensating Transactions)
In distributed systems (Sagas pattern), if a transaction fails halfway through, we run Compensating Transactions to undo the partial work. LAMs require this natively. If an agent books a flight but fails to book the hotel, it must know how to cancel the flight.
Architectural Requirement: Every tool definition provided to the LLM should ideally have a corresponding inverse_tool.
create_user->delete_userreserve_inventory->release_inventory
If an action is irreversible (e.g., send_email), gate it behind a high-confidence threshold or human approval.
The Deterministic Wrapper
Building a system for 10M requests/day is about managing variance. LLMs are engines of variance.
To succeed, invert the common design pattern. Do not put the LLM at the center of your architecture with tools orbiting it. Put your Business Logic, State Machine, and Security Policy at the center. The LLM is just a peripheral service—a very clever, very unreliable function call that translates human intent into your system's internal language.
5 Steps to Production
- Enforce Grammars: Never let an LLM output raw text for a machine interface. Use GBNF or JSON schemas.
- Externalize State: Move memory out of the context window and into Redis/Postgres FSMs.
- Implement Idempotency: Ensure every tool call carries a unique hash to prevent double-execution on retries.
- Sandbox the Model: Apply RBAC to the model's outputs. Treat the model as an untrusted user.
- Define Inverse Actions: Do not deploy a write-action without a corresponding rollback action (Saga pattern).
Trust the code. Verify the model. And never let an agent write to your database without a signed, deterministic permit.
References
- [2412.10047] Large Action Models: From Inception to Implementation
- researchgate.net
- Large Action Models (LAMs) With Examples and Challenges
- researchgate.net
- Large Action Models (LAMs): The Next Evolution in AI for 2025
- Microsoft’s Large Action Models (LAMs) Set New AI Benchmark
- reva.edu.in
- The State of AI in 2024-2025: What McKinsey's Latest Report Reveals About Enterprise Adoption
- mckinsey.com
- Large Action Models: Applications and Benefits in 2025
- bluebash.co
- 10 Large Action Model Startups to Watch in 2025
- Agentic AI Architecture
- LLM-based Agents
- Top 5 Tools for AI Agent Observability in 2025
- medium.com
- medium.com
- Best Practices for Responsible AI Deployment in Enterprise AI Systems
- AI Model Governance Framework for US Enterprises
- Enterprise AI Governance: A Complete Guide For Organizations